共享所有权
一个动态分配的对象可以在多个shared_ptr之间共享,这是因为shared_ptr支持 copy 操作:
原理介绍
shared_ptr内部包含两个指针,一个指向对象,另一个指向控制块(control block),控制块中包含一个引用计数和其它一些数据。由于这个控制块需要在多个shared_ptr之间共享,所以它也是存在于 heap 中的。shared_ptr对象本身是线程安全的,也就是说shared_ptr的引用计数增加和减少的操作都是原子的。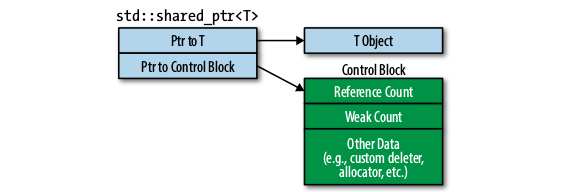
通过unique_ptr来构造shared_ptr是可行的:
shared_ptr 的风险
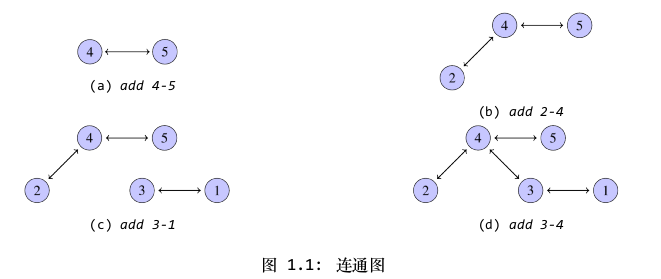
你大概觉得使用智能指针就再也高枕无忧了,不再为内存泄露烦恼了。然而梦想总是美好的,使用shared_ptr时,不可避免地会遇到循环引用的情况,这样容易导致内存泄露。循环引用就像下图所示,通过shared_ptr创建的两个对象,同时它们的内部均包含shared_ptr指向对方。
分析一下main函数是如何退出的,一切就都明了:
main函数退出之前,Father和Son对象的引用计数都是2。son指针销毁,这时Son对象的引用计数是1。father指针销毁,这时Father对象的引用计数是1。- 由于
Father对象和Son对象的引用计数都是1,这两个对象都不会被销毁,从而发生内存泄露。
为避免循环引用导致的内存泄露,就需要使用weak_ptr,weak_ptr并不拥有其指向的对象,也就是说,让weak_ptr指向shared_ptr所指向对象,对象的引用计数并不会增加: