微服务介绍
在传统模式下,如果微服务之间要进行通信,那么程序需要自己处理各种通信的细节,这就包括服务发现、熔断机制、超时重试和 tracing 等功能。这些功能通常实现为与某种编程语言相关的 library,这也导致了这样的 library 无法在不同的编程语言之间共享。
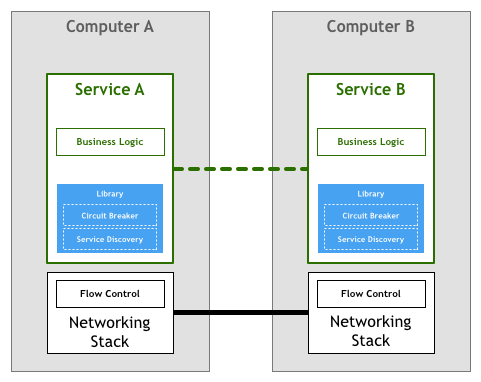
更进一步,如果我们可以将这部分功能抽取出来,形成一个独立的进程,这样的进程称为 Sidecar。通常来说,我们会将应用程序和 Sidecar 部署在一起,那么程序的入口流量和出口流量都会由这个 Sidecar 去代理,这样就可以通过 Sidecar 去实现服务发现、熔断机制、超时重试等功能了。
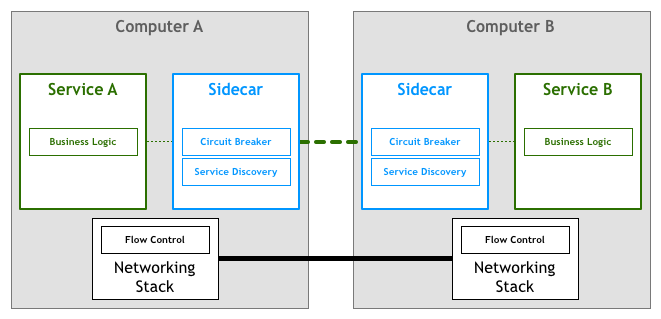
Envoy Proxy 介绍
Envoy Proxy 可以用来充当 Sidecar 进程。通常来说,我们会将应用程序和 Envoy 部署在一起,形成一个微服务。另一方面,为了实现高可用,通常一个微服务会部署多份副本,这些副本加在一起,就形成了 Service Cluster。下图显示的就是服务与服务之间的通信:

除了可以充当 Sidecar 进程之外,Envoy Proxy 还可以充当反向代理,将流量转发给后端的 Service Cluster。充当反向代理的 Envoy,通常也可以称为 Edge Envoy。

构建程序镜像
在部署应用程序之前,需要先构建 Docker 镜像,下面是一个简单的 Flask 程序app.py:1234567891011121314151617import socketfrom flask import Flaskapp = Flask(__name__)def hello_world(): return 'Hello, World!'def healthy_check(): service = socket.gethostname() ip = socket.gethostbyname(service) return 'I am fine! <service_name: {}, ip: {}>'.format(service, ip)if __name__ == '__main__': app.run(debug=True, host='0.0.0.0', port=5000)
具体的 Dockerfile 以及构建镜像需要用到的命令,可以见这里。