NPTL 线程模型
NPTL,也即 Native POSIX Thread Library,是 Linux 2.6 引入的新的线程库实现,用来替代旧的 LinuxThreads 线程库。在 NPTL 实现中,用户创建的每个线程都对应着一个内核态的线程,内核态线程也是 Linux 的最小调度单元。
在 NPTL 实现中,线程的创建相当于调用clone(),并指定下面的参数:12CLONE_VM | CLONE_FILES | CLONE_FS | CLONE_SIGHAND | CLONE_THREAD | CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID | CLONE_SYSVSEM
下面解释一下这些参数的含义:
CLONE_VM所有线程都共享同一个进程地址空间。CLONE_FILES所有线程都共享进程的文件描述符列表 (file descriptor table)。CLONE_FS所有线程都共享同一个文件系统的信息。CLONE_SIGHAND所有线程都共享同一个信号 handler 列表。CLONE_THREAD所有线程都共享同一个进程 ID 以及 父进程 ID。
在 Linux 可以通过下面命令查看线程库的实现方式:12$ getconf GNU_LIBPTHREAD_VERSIONNPTL 2.23
线程的栈
在 Linux 中,一个进程可以包含多个线程,这些线程将共享进程的全局变量,以及进程的堆,但每个线程都拥有它自己的栈。正如下图所示:
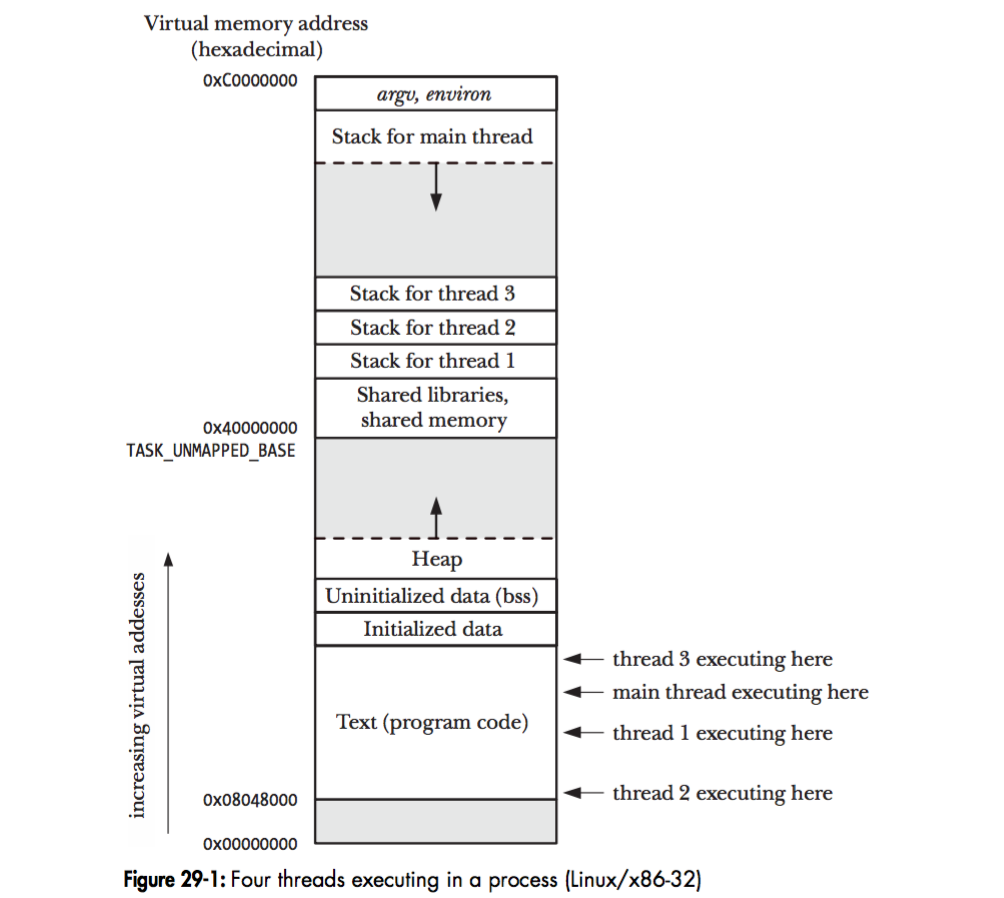
在 64 位系统中,除了主线程之外,其它线程的栈默认大小为 8M,而主线程的栈则没有这个限制,因为主线程的栈可以动态增长。可以用下面的命令查看线程栈的大小:
|
|