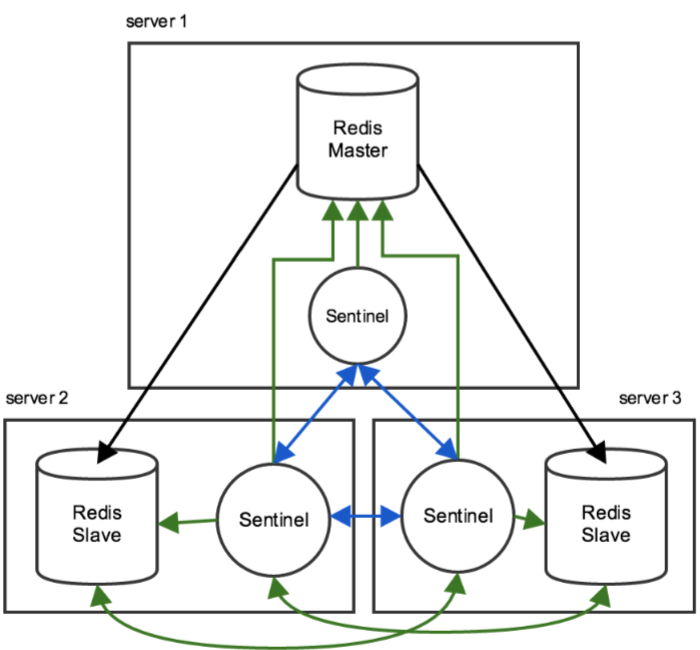
高可用性
Redis Cluster 能自动将数据在多个 master 节点之间分片,从而拓展了 Redis 的读写能力。集群中的每个 master 节点都对应着一个或多个 slave 节点,这也在一定程度上保证了 Redis 的可用性,譬如说,当某个 master 节点发生故障,那么它的其中一个 slave 节点可以提升成为新的 master 节点,从而保证整个集群继续可用。
数据分片
整个集群固定地拥有 16384 个 hash slot,集群中的每个 master 节点都拥有若干个 slot,可以使用下面的算法计算某个 key 被分配到的哪个 slot 中:
集群配置
为了启动集群,每个节点的配置文件redis.conf都需要指定相应的集群配置信息:
对于每个节点来说,它都需要一个配置文件用于记录整个集群的信息。cluster-config-file选项指定了这个配置文件的路径,当集群信息更新时,节点会自动将集群的信息更新到这个配置文件中。
当集群的某个节点不可用(unavailable),通常不会立即认定它发生故障了,因为说不定隔一段时间它就恢复可用了。cluster-node-timeout用来指定节点的最大不可用时间,也就是说当节点的不可用时间超过这个值时,集群就会认为这个节点发生故障了。